UnicodeとUTF-8の違いを理解していない方が結構居るようなので、文字コードの考え方を元に解説してみようと思う。
文字コードとは何か?
文字コードとは、コンピュータ上で文字を扱うために、文字に対して割り当てられた数値のことであり、文字と数値の対応付けと呼べる。
この対応付けの種類は沢山あって、Shift-JISであったり、UTF-8であったりする。
以上!と言いたいけど、文字コードはこんなに単純ではない。文字コードを複雑にする要素は沢山あるが、今回の記事ではUnicodeとUTF-8の違いに焦点を絞って解説してみたいと思う。
文字コードの構成要素
文字コードの世界は以下の2つの要素で構成されている。 この違いを意識しておかないと混乱を招くだろう。
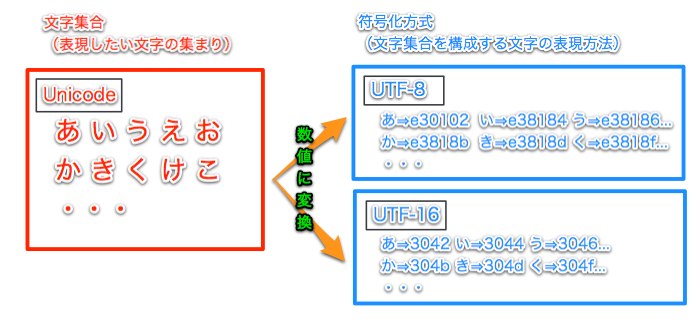
(1).文字集合 – 表現したい文字の範囲(”あ”、”い”・・・といった文字の集合体)
(2).符号化方式 – 文字集合を構成する個々の文字の表現方法(数値の振り方)
世界中には日本語や英語、ドイツ語、中国語・・・など、大量の文字が存在する。これらの文字から表現したい文字の範囲(集合体)を定義する。これが(1)の文字集合だ。
次に(1)の個々の文字をコンピュータ上でどういった数値で表現するかを定義する。この数値の振り方が符号化方式(2)である。コンピュータはこの(2)で割り当てられた数値を用いて文字を表現する。
この文字集合と符号化方式を混合している方がよく居るが、この2つの考え方を理解すればUnicodeとUTF-8の違いも分かるだろう。
つまり
Unicodeは文字集合(1)であり、UTF-8は符号化方式(2)なのだ。
同じようにUnicode用の符号化方式としてUTF-16やUTF-32が存在する。
これらはUnicode文字集合に対する数値の振り方こそ違うものの、同じ文字集合から作られているから、表現できる文字の種類は同じなのだ。
なぜUnicodeとUTF-8を混合してしまうのか?
そもそも文字コードに興味の無い人が多くて、UTF-8はUnicodeの一部ような、ぼんやりしたイメージしか持っていない人が多い。強いて言うなら以下の2つだと思う。
Unicodeを符号化方式として扱っているソフトウェアの存在
よくネタとして挙がるのがWindowsのメモ帳。ファイルを保存する場合、以下の文字コードを選択できる。UTF-8の他に「Unicode」と「Unicode big endian」なるコードも選べてしまう。
この表示、文字集合と符号化方式について理解していても混乱してしまう。
Unicodeって文字集合だよね??
符号化方式ではないのにファイル保存の形式に選べるってどういうこと??
実はWindowsのメモ帳でUnicodeを選択した場合の符号化方式は「UTF-16」と決められている。
「Unicode」と「Unicode big endian」は同じUTF-16だがエンディアンが異なる。
参考 – エンディアンとは
エンディアンとは複数バイトで構成されるデータの並べ方の事で、ビッグエンディアンとリトルエンディアンがある。例えば「0xABCD」という、2バイトのデータがあったとき、これを「ABCD」と並べるか「CDAB」と並べるかが異なる。前者がビッグエンディアン、後者がリトルエンディアンである。人の目から見ると「ABCD」の方が分かりやすいけど、コンピュータ視点で見ると「CDAB」の方が操作しやすい。
(計算は下の桁から始めるから、下位バイトが先に読み込めた方がコンピュータ的には都合が良い。人には見にくいけど)
試してみた。
Windowsのメモ帳でUnicode、Unicode big endian、UTF-8で保存したファイルをそれぞれ用意。
ファイル内の文字はすべて同じ。?
$ ls
Unicode.txt UnicodeBigEndian.txt utf-8.txt
$ cat utf-8.txt
あいうえお
一二三四五
まず、文字コードの確認?
$ nkf --guess utf-8.txt UTF-8 (CRLF) $ nkf --guess Unicode.txt UTF-16 (CRLF) $ nkf --guess UnicodeBigEndian.txt UTF-16 (CRLF)
やはり「Unicode.txt」、「UnicodeBigEndian.txt」は両方ともUTF-16みたいだ。
ついでにエンディアンも確認
今回はodコマンドを利用してファイルのバイナリ表現を出力する。odコマンドはエンディアンに依存した出力を行うため、1バイト単位で区切って出力するために-t x1オプションを付与して実行する。
(今回の環境はリトルエンディアン環境のため、-t x1を付与しないとリトルエンディアンを意識した出力(前後逆にする)となってしまう。)?
$ od -t x1 Unicode.txt 0000000 ff fe 42 30 44 30 46 30 48 30 4a 30 0d 00 0a 00 0000020 00 4e 8c 4e 09 4e db 56 94 4e $ od -t x1 UnicodeBigEndian.txt 0000000 fe ff 30 42 30 44 30 46 30 48 30 4a 00 0d 00 0a 0000020 4e 00 4e 8c 4e 09 56 db 4e 94
やはり「Unicode.txt」はリトルエンディアンで、「UnicodeBigEndian」はビッグエンディアンだ。
ちなみに、エンディアンはファイルの先頭2バイトで確認できる。
この2バイトの事をBOM(ByteOrderMark)といい、エンディアンの判別に利用される。
(BOMが付与されていない場合はビッグエンディアンとして扱われる)
BOMが
「fffe」の場合:リトルエンディアン
「feff」の場合:ビッグエンディアン
と判別できる。
コードポイントが紛らわしい
文字集合にはコードポイントという符号化方式とは異なる数値の振り方がある。
コードポイントとは?
文字集合では、個々の文字に対して、文字集合内での符号位置が決められている。これをコードポイントという。
言い方を変えると、「文字集合を構成する文字を並べて、頭から順番に振った数値」のことだ。
このコードポイントはあくまで”その文字の文字集合内での位置”であり、符号化方式ではない。
例えば「ほげふが」のUnicodeのコードポイントは以下の通りである。
| 文字 | コードポイント |
|---|---|
| ほ | U+307B |
| げ | U+3052 |
| ふ | U+3075 |
| が | U+304C |
このU+XXXXはただの符号位置を表す数値なので、この値でデータを保存しても意味が無い。
文字を表現したい場合はコードポイントではなく、符号化されたByte列を用いる必要があるのだ。
このコードポイント、ぱっと見で符号化方式に見えてしまう。この点を理解していない方は混乱すると思う。
コードポイントの利用場面
コードポイントは様々な場面で利用されている。例えばJavaのプロパティファイル(.propertiesファイル)に日本語を記述する場合などだ。
Javaのプロパティファイルは文字コード「ISO-8859-1」で記述するというルールがある。
「ISO-8859-1」はほとんどASCII文字しか扱えなから、表現したい文字のUnicodeコードポイントをプロパティファイルに記述する。
例えば、「message=こんにちは」といったプロパティを定義する場合、?
message=\u3053\u3093\u306B\u3061\u306F
と定義する必要がある。
\uは後続の文字がコードポイントを表していることを指し、その後ろにコードポイントを記載する。コードポイントの指す文字は「こんにちは」であるが、コードポイント自体は数値とアルファベットでのみ構成されるため、「ISO-8859-1」でも問題無く保存できるという訳だ。
この文字からコードポイントへの変換は通常IDEが自動的に実施するが、ファイルの実体はUnicodeコードポイントで表現されている。
また、「native2ascii」を使えばファイル内の「ISO-8859-1」が表現できない文字を手動でUnicodeコードポイントに変換できる。
※ ちなみに、J2SE 5.0からはxml形式のプロパティファイルを扱えるようになり、これをを利用すれば自由に文字コード指定できるようになった。
これ以外にもUnicodeコードポイントを利用する例は多々あるが、コードポイントは符号位置(文字集合内の文字の位置)であって、符号化方式ではない。そのためコードポイントはUnicodeの符号化方式であるUTF-8やUTF-16とは直接は関係しない。
コメントを残す